Reposted from April 2023
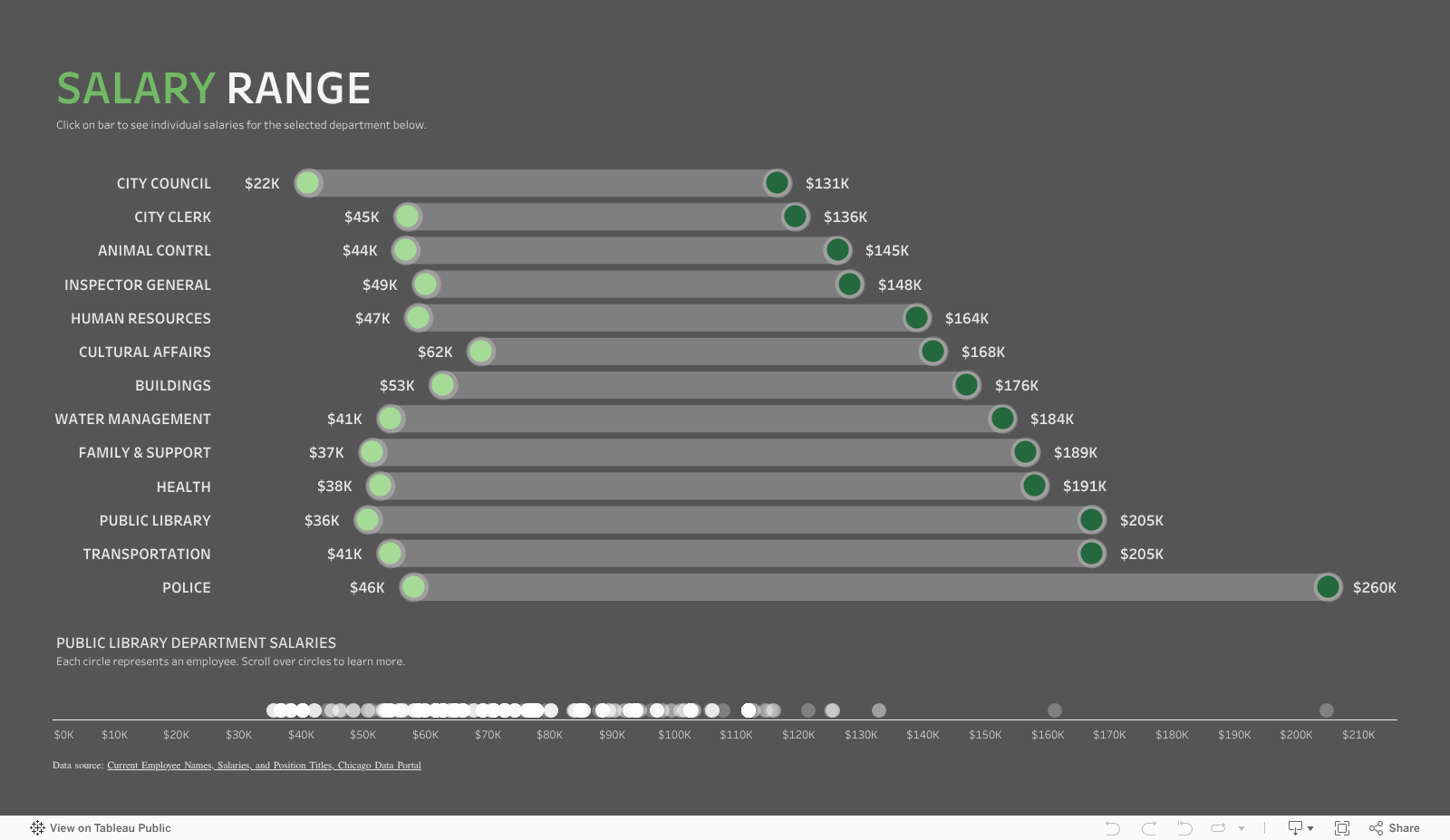
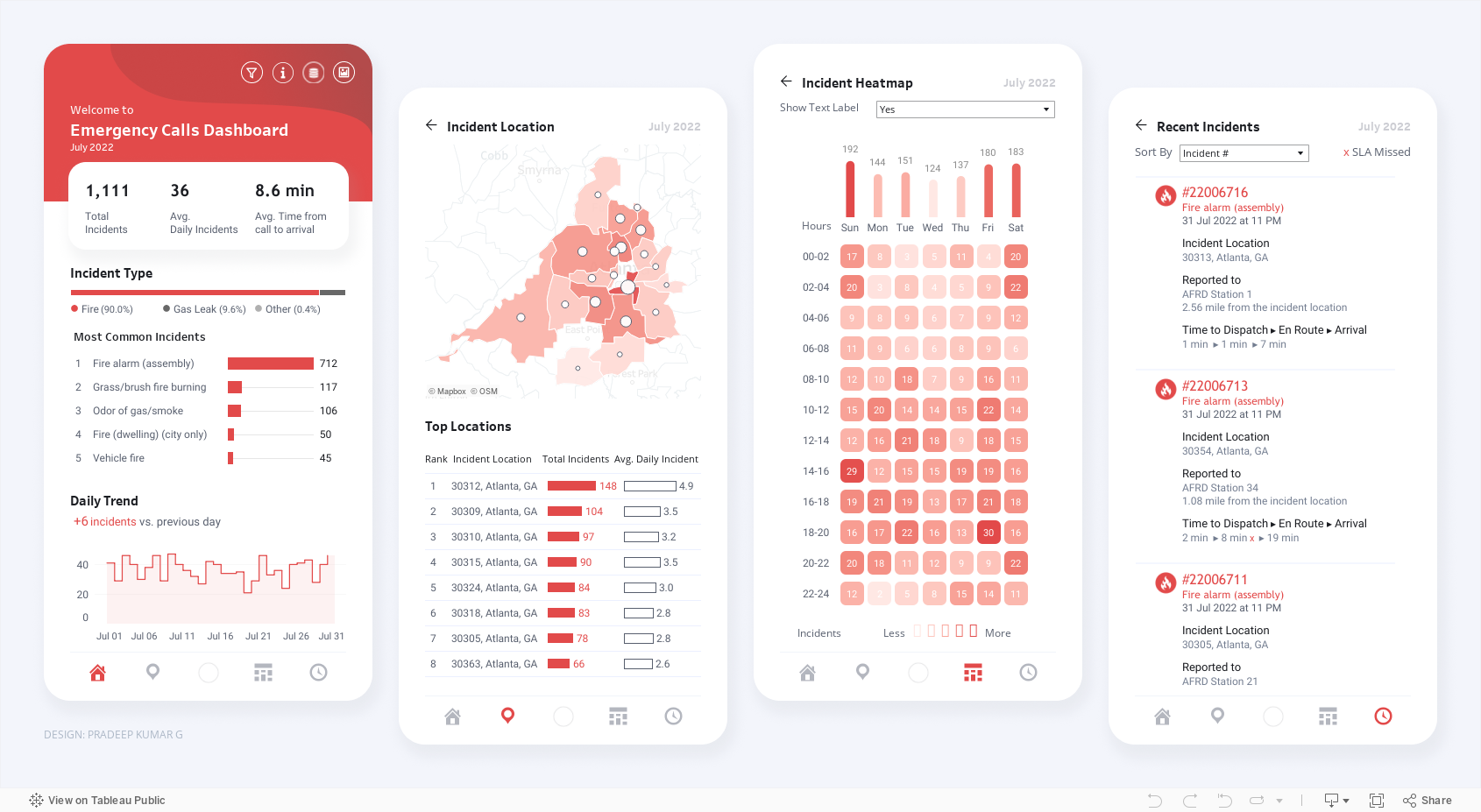
Today I offer up yet another steal-worthy viz: Emergency Calls Dashboard created with Tableau by Pradeep Kumar G. This one is genius. It seems to defy basic graphic design rules. It includes many charts and lots of small text and numbers and yet it’s readable and not overwhelming.

As you can see, the charts are contained within four rectangular views, each with the dimensions of a phone screen. Tableau dashboards can include layouts for different types of devices with varying screen sizes. When you publish these layouts, people viewing your dashboard experience a design optimized for their device (phone, tablet, or desktop.)
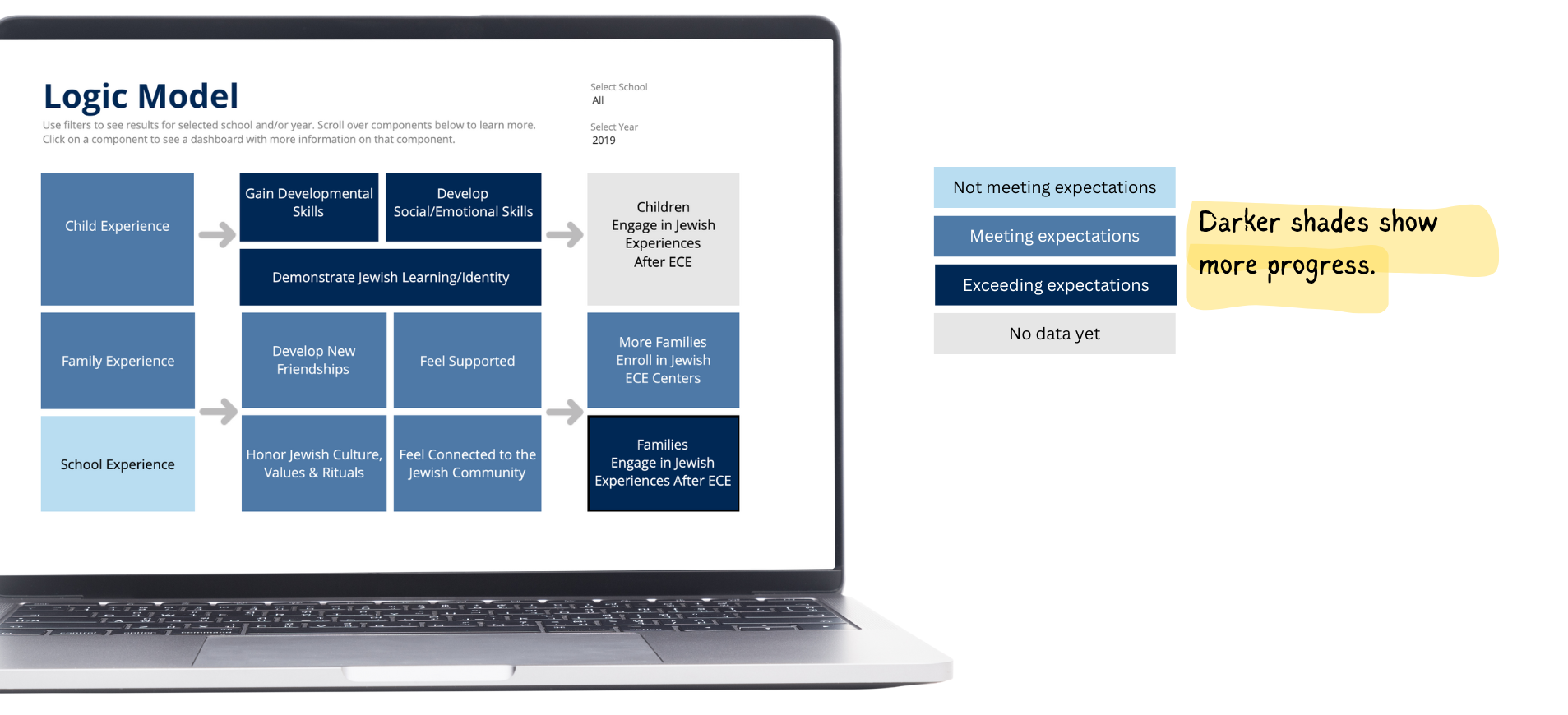
If you view the Emergency Calls Dashboard with a phone, you will see just one of the four views and can use the icons at the bottom of the screen to navigate to the other views, as shown in the image to the right.
Effective phone layouts usually:
Limit a dashboard’s focus and content (you can only get so much on this small canvas),
Reduce interactivity (dealing with filters on a phone can be annoying*), and
Use a vertical orientation (vertical scrolling is easier than horizontal scrolling).
The Emergency Calls Dashboard has all of these features, so the phone view works quite well. Indeed, these phone views are so effective that they also work when laid out side-by-side in the desktop view.
When building dashboards for multiple device types, dashboard designers often start with the desktop view and then simplify that larger, more detailed design for the phone view. The Emergency Calls Dashboard demonstrates the benefit of beginning with the phone view. If you design a simple, readable phone view that makes effective use of its limited canvas, you can use this design to fit more information in the desktop or tablet layout. Even if you aren’t designing for multiple screen sizes, following the tips for effective phone layouts will serve you well, opening up possibilities for including more data in one view without overwhelming the user.
I’ve embedded the dashboard below so that you can interact with it.
*The Tableau Mobile app optimizes filters for phones, making them pop and easier to use. It also allows for logical scrolling, swiping, pinching, and zooming. However, some of your users may not use the app.
Let’s talk about YOUR data!
Got the feeling that you and your colleagues would use your data more effectively if you could see it better? Data Viz for Nonprofits (DVN) can help you get the ball rolling with an interactive data dashboard and beautiful charts, maps, and graphs for your next presentation, report, proposal, or webpage. Through a short-term consultation, we can help you to clarify the questions you want to answer and goals you want to track. DVN then visualizes your data to address those questions and track those goals.